


![]()
SWXMLHash 是一种在 Swift 中解析 XML 的相对简单的方法。如果你熟悉 XMLParser (以前的 NSXMLParser),那么这个库是对它的封装。从概念上讲,它提供了从 XML 到数组字典(也称为哈希)的转换。
该 API 从 SwiftyJSON 中汲取了大量灵感。
- iOS 8.0+ / Mac OS X 10.9+ / tvOS 9.0+ / watchOS 2.0+
- Xcode 8.0+
可以使用 Swift Package Manager、CocoaPods、Carthage 或手动安装 SWXMLHash。
Swift Package Manager 是 Apple 构建的工具,作为 Swift 项目 的一部分,用于将库和框架集成到你的 Swift 应用程序中。
要添加 SWXMLHash 作为依赖项,请更新 Package.swift 中的 dependencies,使其包含如下引用
dependencies: [
.package(url: "https://github.com/drmohundro/SWXMLHash.git", from: "7.0.0")
]
然后 swift build 应该会拉取并编译 SWXMLHash 以开始使用。
要安装 CocoaPods,请运行
gem install cocoapods
然后创建一个包含以下内容的 Podfile
platform :ios, '10.0'
use_frameworks!
target 'YOUR_TARGET_NAME' do
pod 'SWXMLHash', '~> 7.0.0'
end
最后,运行以下命令进行安装
pod install
要安装 Carthage,请运行(使用 Homebrew)
brew update
brew install carthage
然后将以下行添加到你的 Cartfile
github "drmohundro/SWXMLHash" ~> 7.0
要手动安装,你需要克隆 SWXMLHash 存储库。 你可以在单独的目录中执行此操作,也可以使用 git 子模块 - 在这种情况下,建议使用 git 子模块,以便你的存储库具有有关你正在使用的 SWXMLHash 的哪个提交的详细信息。 完成后,你可以将所有相关的 swift 文件放入你的项目中。
但是,如果你使用的是工作区,则可以包含整个 SWXMLHash.xcodeproj。
如果你刚开始使用 SWXMLHash,我建议克隆存储库并打开工作区。 我在工作区中包含了一个 Swift playground,可以方便地试验 API 和调用。
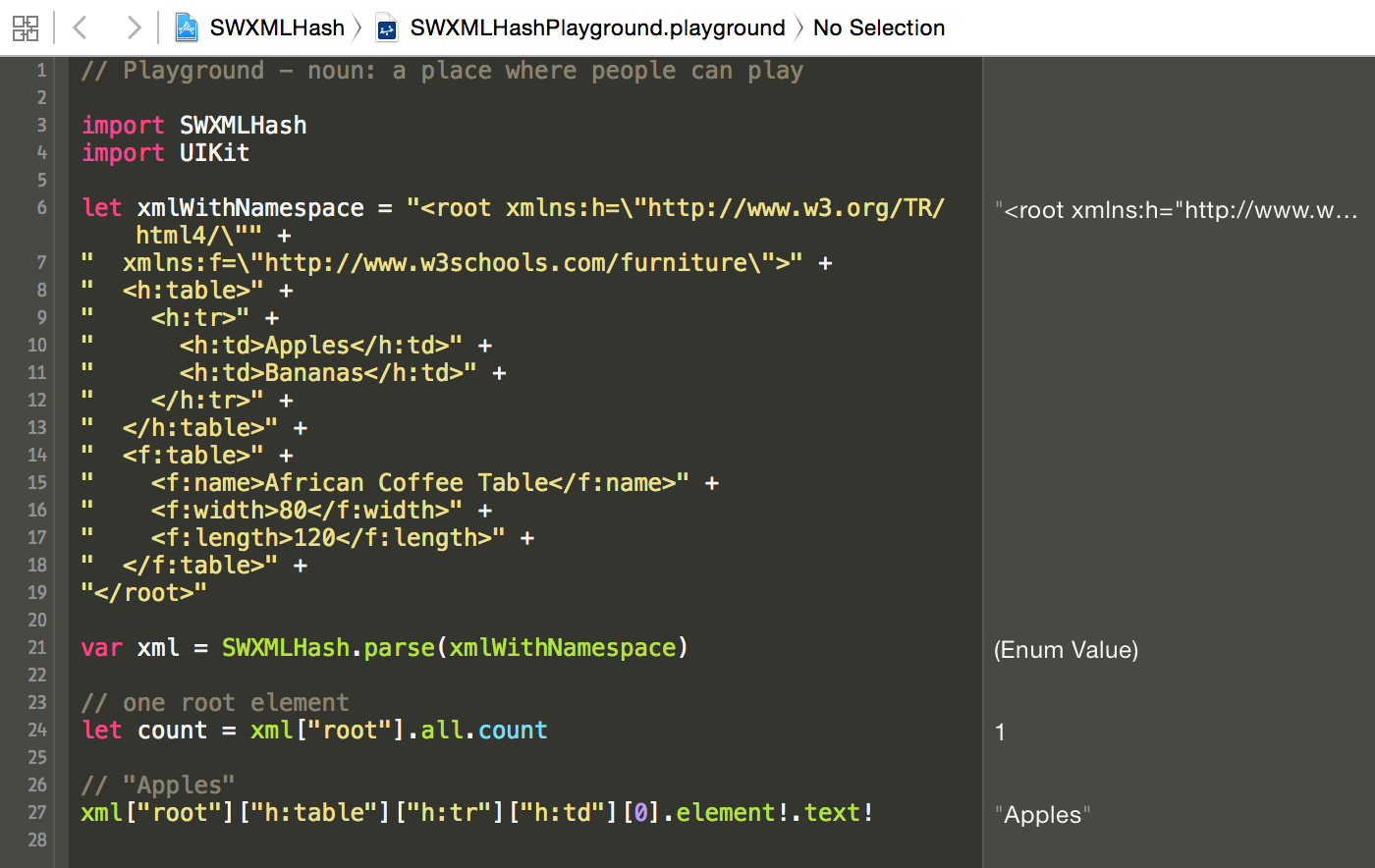
SWXMLHash 允许对其解析方法进行有限的配置。 要设置任何配置选项,可以使用 configure 方法,如下所示
let xml = XMLHash.config {
config in
// set any config options here
}.parse(xmlToParse)
此时可用的选项是
shouldProcessLazily- 这决定了是否使用 XML 的延迟加载。 如果你的 XML 很大,它可以显着提高解析性能。
- 默认为
false
shouldProcessNamespaces- 此设置会转发到内部
NSXMLParser实例。 它将返回任何没有命名空间部分的 XML 元素(即 "<h:table>" 将作为 "<table>" 返回) - 默认为
false
- 此设置会转发到内部
caseInsensitive- 此设置允许键查找不区分大小写。 通常,XML 是一种区分大小写的语言,但如果需要,此选项允许你绕过它。
- 默认为
false
encoding- 当 XML 字符串传递给
parse时,此设置允许显式指定字符编码。 - 默认为
String.encoding.utf8
- 当 XML 字符串传递给
userInfo- 此设置模仿
Codable的userInfo属性,允许用户添加将用于反序列化的上下文信息。 - 请参阅 Codable 的 userInfo 文档
- 默认值为 [:]
- 此设置模仿
detectParsingErrors- 此设置尝试检测 XML 解析错误。 如果发现任何解析问题,
parse将返回一个XMLIndexer.parsingError。 - 默认为
false(因为向后兼容性,以及许多用户尝试使用此库解析 HTML)
- 此设置尝试检测 XML 解析错误。 如果发现任何解析问题,
以下所有示例都可以在包含的 specs 中找到。
let xml = XMLHash.parse(xmlToParse)
或者,如果要解析大型 XML 文件并需要最佳性能,你可能希望将解析配置为延迟处理。 延迟处理避免将整个 XML 文档加载到内存中,因此出于性能原因,它可能是首选。 请参阅错误处理,了解有关延迟加载的一个注意事项。
let xml = XMLHash.config {
config in
config.shouldProcessLazily = true
}.parse(xmlToParse)
上述方法使用 config 方法,但 XMLHash 上也有一个直接的 lazy 方法。
let xml = XMLHash.lazy(xmlToParse)
给定
<root>
<header>
<title>Foo</title>
</header>
...
</root>
将返回 "Foo"。
xml["root"]["header"]["title"].element?.text
给定
<root>
...
<catalog>
<book><author>Bob</author></book>
<book><author>John</author></book>
<book><author>Mark</author></book>
</catalog>
...
</root>
以下将返回 "John"。
xml["root"]["catalog"]["book"][1]["author"].element?.text
给定
<root>
...
<catalog>
<book id="1"><author>Bob</author></book>
<book id="123"><author>John</author></book>
<book id="456"><author>Mark</author></book>
</catalog>
...
</root>
以下将返回 "123"。
xml["root"]["catalog"]["book"][1].element?.attribute(by: "id")?.text
或者,你可以查找具有特定属性的元素。 以下将返回 "John"。
xml["root"]["catalog"]["book"].withAttribute("id", "123")["author"].element?.text
给定
<root>
...
<catalog>
<book><genre>Fiction</genre></book>
<book><genre>Non-fiction</genre></book>
<book><genre>Technical</genre></book>
</catalog>
...
</root>
all 方法将迭代索引级别的所有节点。 以下代码将返回 "Fiction, Non-fiction, Technical"。
", ".join(xml["root"]["catalog"]["book"].all.map { elem in
elem["genre"].element!.text!
})
你也可以迭代 all 方法
for elem in xml["root"]["catalog"]["book"].all {
print(elem["genre"].element!.text!)
}
给定
<root>
<catalog>
<book>
<genre>Fiction</genre>
<title>Book</title>
<date>1/1/2015</date>
</book>
</catalog>
</root>
以下将 print "root"、"catalog"、"book"、"genre"、"title" 和 "date"(注意 children 方法)。
func enumerate(indexer: XMLIndexer) {
for child in indexer.children {
print(child.element!.name)
enumerate(child)
}
}
enumerate(indexer: xml)
给定
<root>
<catalog>
<book id="bk101">
<author>Gambardella, Matthew</author>
<title>XML Developer's Guide</title>
<genre>Computer</genre><price>44.95</price>
<publish_date>2000-10-01</publish_date>
</book>
<book id="bk102">
<author>Ralls, Kim</author>
<title>Midnight Rain</title>
<genre>Fantasy</genre>
<price>5.95</price>
<publish_date>2000-12-16</publish_date>
</book>
<book id="bk103">
<author>Corets, Eva</author>
<title>Maeve Ascendant</title>
<genre>Fantasy</genre>
<price>5.95</price>
<publish_date>2000-11-17</publish_date>
</book>
</catalog>
</root>
以下将返回 "Midnight Rain"。 过滤可以按 XMLElement 类的任何部分进行,也可以按索引进行。
let subIndexer = xml!["root"]["catalog"]["book"]
.filterAll { elem, _ in elem.attribute(by: "id")!.text == "bk102" }
.filterChildren { _, index in index >= 1 && index <= 3 }
print(subIndexer.children[0].element?.text)
使用 Do-Catch 和 Errors
do {
try xml!.byKey("root").byKey("what").byKey("header").byKey("foo")
} catch let error as IndexingError {
// error is an IndexingError instance that you can deal with
}
或者 使用现有的索引功能
switch xml["root"]["what"]["header"]["foo"] {
case .element(let elem):
// everything is good, code away!
case .xmlError(let error):
// error is an IndexingError instance that you can deal with
}
请注意,如上所示的错误处理不适用于延迟加载的 XML。 延迟解析实际上直到调用 element 或 all 方法才会发生 - 因此,在请求元素之前,无法知道它是否存在。
更常见的情况是,你希望将 XML 树反序列化为自定义类型的数组。 这是 XMLObjectDeserialization 发挥作用的地方。
给定
<root>
<books>
<book isbn="0000000001">
<title>Book A</title>
<price>12.5</price>
<year>2015</year>
<categories>
<category>C1</category>
<category>C2</category>
</categories>
</book>
<book isbn="0000000002">
<title>Book B</title>
<price>10</price>
<year>1988</year>
<categories>
<category>C2</category>
<category>C3</category>
</categories>
</book>
<book isbn="0000000003">
<title>Book C</title>
<price>8.33</price>
<year>1990</year>
<amount>10</amount>
<categories>
<category>C1</category>
<category>C3</category>
</categories>
</book>
</books>
</root>
Book struct 实现 XMLObjectDeserialization
struct Book: XMLObjectDeserialization {
let title: String
let price: Double
let year: Int
let amount: Int?
let isbn: Int
let category: [String]
static func deserialize(_ node: XMLIndexer) throws -> Book {
return try Book(
title: node["title"].value(),
price: node["price"].value(),
year: node["year"].value(),
amount: node["amount"].value(),
isbn: node.value(ofAttribute: "isbn"),
category : node["categories"]["category"].value()
)
}
}
以下将返回 Book struct 的数组
let books: [Book] = try xml["root"]["books"]["book"].value()
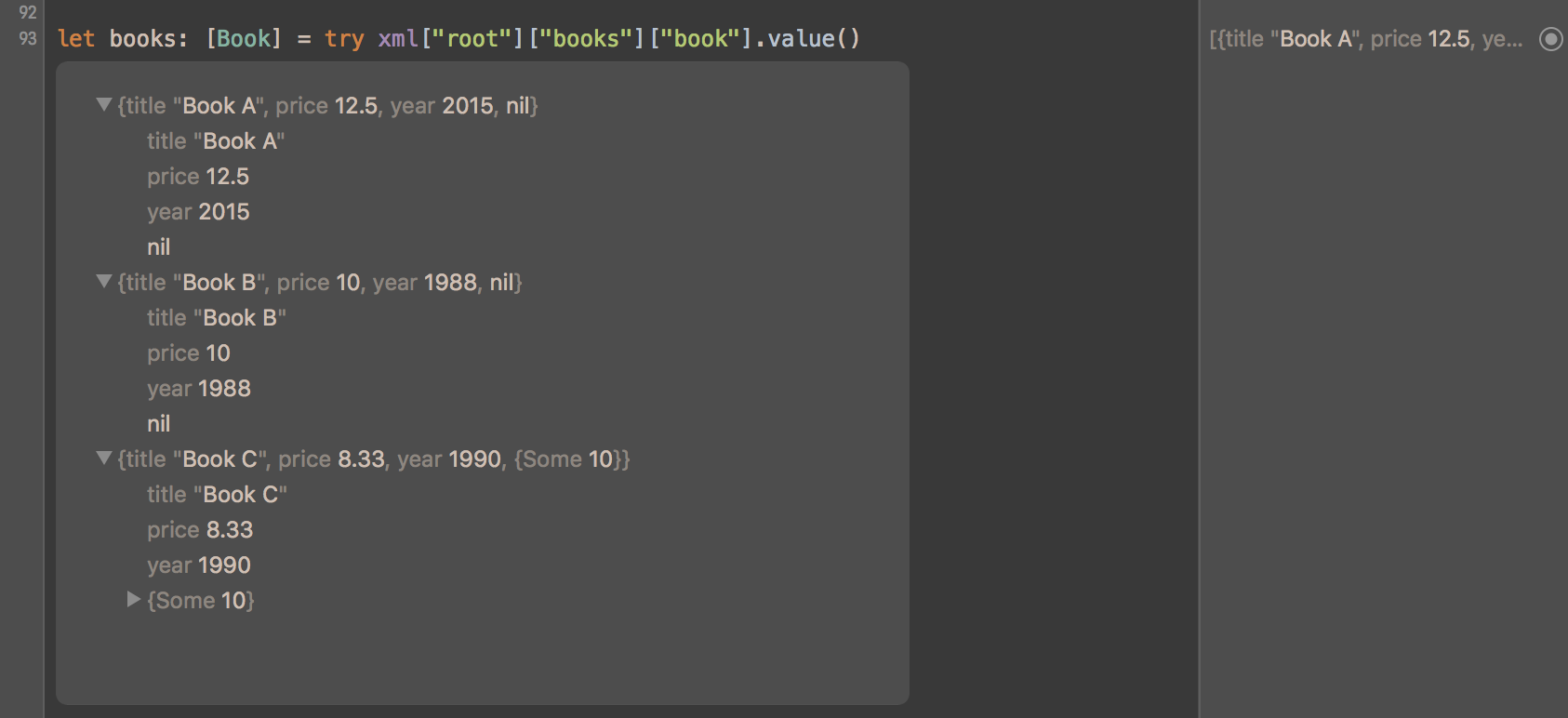
你可以通过为任何非叶节点(例如,上面的 <book>)实现 XMLObjectDeserialization,将任何 XML 转换为你的自定义类型。
对于叶节点(例如,上面的 <title>),内置转换器支持 Int、Double、Float、Bool 和 String 值(包括非可选和可选变体)。 可以通过实现 XMLElementDeserializable 来添加自定义转换器。
对于属性(例如,上面的 isbn=),内置转换器支持与上面相同的类型,并且可以通过实现 XMLAttributeDeserializable 来添加其他转换器。
类型转换支持错误处理、可选和数组。 有关更多示例,请查看 SWXMLHashTests.swift 或直接在 Swift playground 中使用类型转换。
值反序列化是需要将特定字符串值反序列化为自定义类型的地方。 因此,日期是一个很好的例子 - 你宁愿处理日期类型,而不是进行字符串解析,对吗? 这就是 XMLValueDeserialization 属性的用途。
给定
<root>
<elem>Monday, 23 January 2016 12:01:12 111</elem>
</root>
使用以下 Date 值反序列化的实现
extension Date: XMLValueDeserialization {
public static func deserialize(_ element: XMLHash.XMLElement) throws -> Date {
let date = stringToDate(element.text)
guard let validDate = date else {
throw XMLDeserializationError.typeConversionFailed(type: "Date", element: element)
}
return validDate
}
public static func deserialize(_ attribute: XMLAttribute) throws -> Date {
let date = stringToDate(attribute.text)
guard let validDate = date else {
throw XMLDeserializationError.attributeDeserializationFailed(type: "Date", attribute: attribute)
}
return validDate
}
public func validate() throws {
// empty validate... only necessary for custom validation logic after parsing
}
private static func stringToDate(_ dateAsString: String) -> Date? {
let dateFormatter = DateFormatter()
dateFormatter.dateFormat = "EEEE, dd MMMM yyyy HH:mm:ss SSS"
return dateFormatter.date(from: dateAsString)
}
}
以下将返回一个日期值
let dt: Date = try xml["root"]["elem"].value()
不 - SWXMLHash 仅处理 XML 的解析。 如果你有一个 URL,其中包含 XML 内容,我建议使用像 AlamoFire 这样的库将内容下载到字符串中,然后进行解析。
不,目前不支持 - SWXMLHash 仅支持解析 XML(通过索引、反序列化等)。
.value() 用于反序列化 - 你必须有一些实现 XMLObjectDeserialization(或者如果是单个元素而不是一组元素,则实现 XMLElementDeserializable)的东西,并且可以处理到表达式左侧的反序列化。
例如,给定以下内容
let dateValue: Date = try! xml["root"]["date"].value()
你会收到一个错误,因为没有用于 Date 的内置反序列化器。 请参阅上面的文档,了解如何添加你自己的反序列化支持。 在这种情况下,你将为 Date 创建你自己的 XMLElementDeserializable 实现。 请参阅上面,了解如何添加你自己的 Date 反序列化支持的示例。
你的 XML 内容很可能有所谓的“字节顺序标记”或 BOM。 SWXMLHash 使用 NSXMLParser 进行其解析逻辑,并且它在处理 BOM 字符时存在问题。 有关更多详细信息,请参阅 issue #65。 遇到此问题的其他人只是在解析之前从其内容中剥离了 BOM。
在类而不是结构体上使用扩展可能会导致一些奇怪的陷阱,这些陷阱可能会给你带来一些麻烦。 例如,请参阅 StackOverflow 上的这个问题,其中有人试图为 NSDate 编写他们自己的 XMLElementDeserializable,它是一个类而不是一个结构体。 XMLElementDeserializable 协议期望一个返回 Self 的方法 - 这部分有点奇怪。
请参阅下面的代码片段以使其工作,并特别注意 private static func value<T>() -> T 行 - 这是关键。
extension NSDate: XMLElementDeserializable {
public static func deserialize(_ element: XMLElement) throws -> Self {
guard let dateAsString = element.text else {
throw XMLDeserializationError.nodeHasNoValue
}
let dateFormatter = NSDateFormatter()
dateFormatter.dateFormat = "EEE, dd MMM yyyy HH:mm:ss zzz"
let date = dateFormatter.dateFromString(dateAsString)
guard let validDate = date else {
throw XMLDeserializationError.typeConversionFailed(type: "Date", element: element)
}
// NOTE THIS
return value(validDate)
}
// AND THIS
private static func value<T>(date: NSDate) -> T {
return date as! T
}
}
查看 @woolie 在 #245 上的精彩建议/示例。
这与 #256 有关 - 实际上,XMLElement 已经被重命名多次以尝试避免冲突,但最简单的方法是通过 XMLHash.XMLElement 对其进行作用域限定。
请参考#264,其中对此进行了讨论。 唯一需要做的更改是添加以下导入逻辑
#if canImport(FoundationNetworking)
import FoundationNetworking
#endif
请随时给我发送电子邮件,在StackOverflow上发布问题,或者如果您认为您发现了错误,请打开一个 issue。 我很乐意尝试提供帮助!
另一种方法是在Discussions中发布问题。
请参阅CHANGELOG,以获取所有更改及其对应版本的列表。
请参阅CONTRIBUTING,以获取向SWXMLHash贡献代码的指南。
SWXMLHash是在MIT许可证下发布的。 有关详细信息,请参阅LICENSE。